RAGとは?生成AIが社内データを参照する仕組みと活用方法を解説

※本記事は2026/04/16時点での情報を基にしており、閲覧時点では内容や状況が変わっている可能性があります。
生成AIを業務で活用する上で、一般的な回答だけでは対応しきれない場面が増えてきています。RAGは、生成AIが社内データや外部データを検索し、参照して回答する仕組みです。本記事では、RAGの意味・仕組み・活用例と、導入前に整えるべき情報資産について整理します。
目次
RAGとは?生成AIが外部データを参照して回答する仕組み
RAGは、生成AIが外部のデータを検索し、その情報を参照して回答を生成する仕組みです。日本語では「検索拡張生成」と呼ばれます。通常の生成AIが持つ一般的な知識だけではなく、社内文書やFAQなどを回答に反映しやすくする技術として、企業での活用が広がっています。
RAGの読み方と正式名称
RAGは「Retrieval-Augmented Generation」の略称です。日本語では「検索拡張生成」と訳されます。一般的には「ラグ」と読みます。
それぞれの単語を分解すると、Retrievalは「検索・取得」、Augmentedは「拡張された」、Generationは「生成」を意味します。「検索によって取得した情報を使って、回答の生成を拡張する仕組み」と理解するとわかりやすいでしょう。
RAGと通常の生成AIの違い
通常の生成AIは、学習済みの知識と入力されたプロンプトをもとに回答を生成します。そのため、回答に使える情報は学習時点のデータと、プロンプトに含まれる内容に限られます。
RAGは、質問に関連する外部情報を検索してから回答を生成するという手順を踏みます。社内規程、業務マニュアル、ヘルプ記事などを参照した回答に近づけやすいのは、この検索ステップがあるためです。ただし、参照先の情報が正しく整理されていなければ、回答精度は安定しません。RAGの有効性は、AIモデルの性能だけでなく、参照するデータの品質に大きく左右されます。
RAGが「社内データを学習させる仕組み」ではない理由
RAGをめぐって、よく見られる誤解に「社内データをAIに学習させる仕組み」というものがあります。しかし、RAGはモデルに社内データを再学習させる仕組みではありません。
RAGは、質問に関連する情報を外部データから検索し、回答生成時に参照させる仕組みです。「学習」と「参照」は異なります。モデルが社内データを覚え込むのではなく、必要な情報をその都度取りに行くというイメージが正確です。
企業利用では、どの情報を参照させるか、どの範囲まで参照できるかという設計が重要になります。参照する情報が多ければよいわけではなく、質と範囲の設計が精度に直結します。
なぜ企業でRAGが注目されているのか
RAGが企業で注目される背景には、生成AIを業務で使う際の限界があります。生成AIは一般的な知識には強い一方、企業ごとの社内情報や個別のルールを最初から知っているわけではありません。企業が保有する情報資産を回答に活かすために、RAGが必要とされています。
生成AIは社内ルールや個別業務を最初から知らない
生成AIは幅広い一般知識を持っていますが、企業ごとの規程、商品仕様、顧客対応ルール、社内手順は把握していません。自社のFAQや業務マニュアルの内容を反映した回答を得るには、何らかの方法で情報を提供する必要があります。
プロンプトに毎回社内文書を貼り付ける運用は、手間がかかる上に入力できる量にも限界があります。RAGを使うと、質問の内容に合わせて必要な社内情報を自動的に検索し、回答に使いやすくなります。
ハルシネーション対策としてRAGが使われる
ハルシネーションとは、生成AIが事実と異なる内容をもっともらしく出力してしまう問題です。RAGは参照情報をもとに回答を生成するため、根拠のない回答を減らす助けになります。
ただし、RAGを使ってもハルシネーションが完全になくなるわけではありません。参照元の情報の品質、検索精度、回答ルールの設計、レビュー体制の整備が、リスクを下げる上で重要です。
最新情報や社内ナレッジを回答に反映しやすい
生成AIが学習した時点に含まれない情報も、RAGなら外部データとして参照できます。更新済みの業務マニュアル、最新の製品仕様、改訂されたFAQなどを回答に反映しやすい点が、変化の多い業務で評価されています。
モデルを再学習させるよりも参照データを更新する方が、運用の手間は少なくて済みます。ただし、古い情報が参照先に残っていると誤回答の原因になります。情報の更新管理は、RAG運用の重要な要素です。
RAGの仕組みをわかりやすく解説
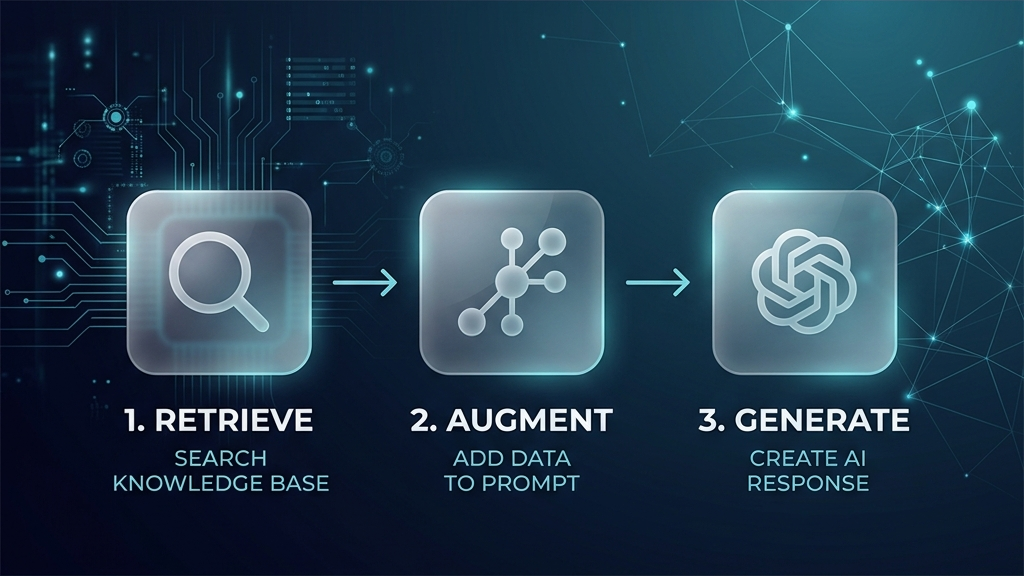
RAGは大きく「検索」「拡張」「生成」の流れで理解できます。ユーザーの質問に対して、まず関連する情報を検索し、その情報を生成AIの入力に加えた上で、AIが参照情報をもとに回答を作ります。
質問に関連する情報を検索する
ユーザーが質問すると、システムはまず関連する文書やデータを検索します。検索対象は、社内FAQ、業務マニュアル、ヘルプ記事、ナレッジベースなどです。
キーワードの完全一致だけでなく、文章の意味の近さをもとにした検索が使われることもあります。この検索ステップの精度が回答品質に大きく影響するため、検索対象のデータをどう整理するかが重要になります。
検索した情報をプロンプトに加える
検索で取得した情報を、生成AIへの入力に追加します。生成AIは、その参照情報を材料にして回答を作ります。
参照情報が長すぎたり、重複していたり、文脈が不足していたりすると、回答がぶれやすくなります。文書の見出しの付け方、1文書あたりの情報量や区切り方なども、このステップの精度に影響します。
生成AIが参照情報をもとに回答を作る
生成AIは、検索された情報を踏まえて自然な文章で回答を生成します。社内ルールや製品情報などを参照した回答に近づけやすくなります。
ただし、参照情報を誤って解釈するリスクは残ります。参照元の文書名を回答とともに表示する設計や、回答をレビューする仕組みを入れると、業務での利用がしやすくなります。
RAGでできることと主な活用例
RAGは、社内情報や顧客向け情報を生成AIで活用しやすくします。特に、問い合わせ対応、社内ヘルプデスク、研修、営業支援と相性がよい技術です。活用例は「自動化」よりも「必要な情報に到達しやすくする」という文脈で整理するとわかりやすくなります。
社内FAQや業務マニュアルの検索性を高める
社内FAQや業務マニュアルは存在していても、必要なときに探しにくいことがよくあります。RAGを使うと、自然文の質問から関連するルールや手順を探しやすくなります。
社内ヘルプデスクや情報システム部門、総務・人事への問い合わせの効率化に活用できます。ただし、FAQやマニュアルに重複する情報や古い情報が残っていると、回答精度が下がります。参照前の整理が前提になります。
カスタマーサポートの自己解決を支援する
ヘルプ記事やFAQをRAGに接続すると、顧客の質問に合う回答を提示しやすくなります。CS領域では、問い合わせ件数の削減だけでなく「顧客が最後まで解決に到達できるか」が重要な指標になります。
解決到達率を上げるには、ヘルプ記事、FAQ、操作説明、トラブルシューティング情報の整備が前提です。RAGを接続するだけでは解決率は上がりません。情報の質が成果に直結します。
研修資料やオンボーディング資料を活用しやすくする
研修資料やオンボーディング資料は、作成された後に読まれなくなることがあります。RAGを使うと、社員が必要なタイミングで資料内の情報を探しやすくなります。
L&D領域では、研修資料を「検索できる学習資産」に変えるという視点が重要です。新入社員、異動者、リモート社員、店舗スタッフなど、必要な情報にアクセスしにくい立場の人ほど、RAGによる検索支援の効果が出やすいといえます。
営業資料や提案ナレッジを再利用しやすくする
営業資料・提案書・導入事例・過去のFAQをRAGで参照しやすくすると、提案準備を効率化できます。過去の提案内容や顧客別の説明資料を探しやすくなり、属人化した営業ナレッジの共有にもつながります。
ただし、顧客情報や機密情報が含まれる文書については、誰がアクセスできるかという権限設計が必要です。参照できる情報を用途や職種によって制限する仕組みを設けることが前提になります。
RAGとファインチューニングの違い

RAGとファインチューニングは混同されやすい技術です。RAGは外部情報を参照させる方法であり、ファインチューニングはモデルの振る舞いや回答傾向を調整する方法です。社内情報を最新の状態で使いたいなら、まずRAGが選択肢になりやすいといえます。
RAGは外部情報を参照して回答する
RAGは、モデルの外にある情報を検索して回答に使います。情報を更新したいときは、参照先の文書を更新すれば済みます。社内FAQ、業務マニュアル、ヘルプ記事など、内容が変化しやすい情報との相性がよい方法です。
参照元の文書を示しやすい点も、業務利用上のメリットになります。「この回答はどこから来たのか」を確認できることは、誤回答への対応や文書改善の観点からも有効です。
ファインチューニングはモデルの振る舞いを調整する
ファインチューニングは、追加データを使ってモデルの応答傾向を調整する方法です。回答の形式を統一したり、特定の分類タスクに適応させたりする用途に使われます。
最新の社内情報を都度反映する用途では、ファインチューニングは運用負荷が高くなりやすい点に注意が必要です。RAGと対立する方法ではなく、目的に応じて使い分けるものと理解するとよいでしょう。
企業の社内データ活用では使い分けが重要
社内文書やFAQを参照させたいならRAGが向いています。特定の回答形式や判断基準を調整したいならファインチューニングも検討対象になります。両方を組み合わせる構成を採用する企業もあります。
いずれの方法を選ぶにしても、まず「何を実現したいのか」を整理することが出発点です。技術の選定は、業務目標の整理の後に行うものです。
RAG導入前に整えるべき社内データ
RAGの精度は、AIモデルだけでなく参照データの品質に大きく左右されます。社内データが古かったり、重複していたり、権限設計が曖昧だったりすると、誤回答の原因になります。導入前に、情報資産の棚卸しと整備を行うことが重要です。
古い情報や重複情報を整理する
同じテーマの文書が複数存在すると、RAGがどれを参照すべきかが曖昧になります。古い規程や過去のFAQが残っていると、誤った内容を回答の根拠にするリスクがあります。
更新日、最新版、廃止済み文書を整理し、「参照してよい情報」と「参照しない情報」を明確に分けることが大事です。文書管理のルールを事前に定めておくと、この整理がスムーズになります。
文書の粒度と見出し構造をそろえる
長すぎる文書や見出しのない資料は、RAGが適切に参照しにくくなります。1つの文書に複数のテーマが混在していると、回答がぶれやすくなります。
FAQは一問一答型、手順書はステップ型、トラブル対応は症状別にまとめると、RAGが情報を参照しやすくなります。AIが理解しやすい単位に情報を分けるという発想で、文書を見直すことが重要です。
情報の所有者と更新責任を決める
RAG導入後も、参照情報は継続的に更新する必要があります。誰が内容を確認し、誰が更新するかを決めておかないと、情報が古くなるにつれて回答精度が下がります。
部門ごとに情報の管理責任を明確にし、更新のサイクルを設計することが重要です。更新されないナレッジベースは、時間とともに回答品質を損なう原因になります。
権限設計とセキュリティを確認する
RAGでは、参照できる情報の範囲を用途や職種に応じて制御する必要があります。全社員に見せてよい情報と、役職・部署ごとに限定すべき情報を分けることが前提です。
顧客情報、個人情報、契約情報、未公開の情報については特に注意が必要です。「検索できること」と「見せてよいこと」は別の設計として扱う必要があります。
RAGの精度を高めるための運用ポイント
RAGは導入して終わりではありません。回答精度を高め、維持するには、利用状況をもとに継続的に改善する必要があります。モデル、検索、文書、権限、プロンプトを定期的に見直す視点が重要です。
回答精度はモデルだけで決まらない
高性能な生成AIを使っても、参照データが整理されていなければ回答品質は上がりません。検索対象の設定、文書の構造、メタデータの整備、情報の更新状態が、精度に直結します。
企業のRAG活用において「AIの性能」と同等以上に重要なのが「情報設計の品質」です。情報資産を継続的に整備できるかどうかが、他社との差別化につながります。
参照元を確認できる状態にする
業務で利用する上で、回答がどの情報を根拠にしているかを確認できることは重要です。参照元の文書名、更新日、該当箇所を表示できる設計にすると、利用者が回答を検証しやすくなります。
誤回答があったとき、参照元が分かれば改善すべき文書を特定できます。回答精度の向上と信頼性の確保を両立させる上で、参照元の可視化は有効な設計です。
利用ログから改善すべき情報を見つける
ユーザーの質問ログや未解決ログを分析すると、不足している情報が見えてきます。CSでは、検索しても解決に至らない質問を改善対象にすることで、解決到達率の向上につながります。
L&D領域では、社員が繰り返し質問するテーマを研修資料の見直しに活かせます。RAGは社内情報の不足や分かりにくさを発見する手段にもなります。利用ログは、情報資産の改善計画を立てる上での重要なインプットです。
RAGの発展形として知っておきたい新しいトピック
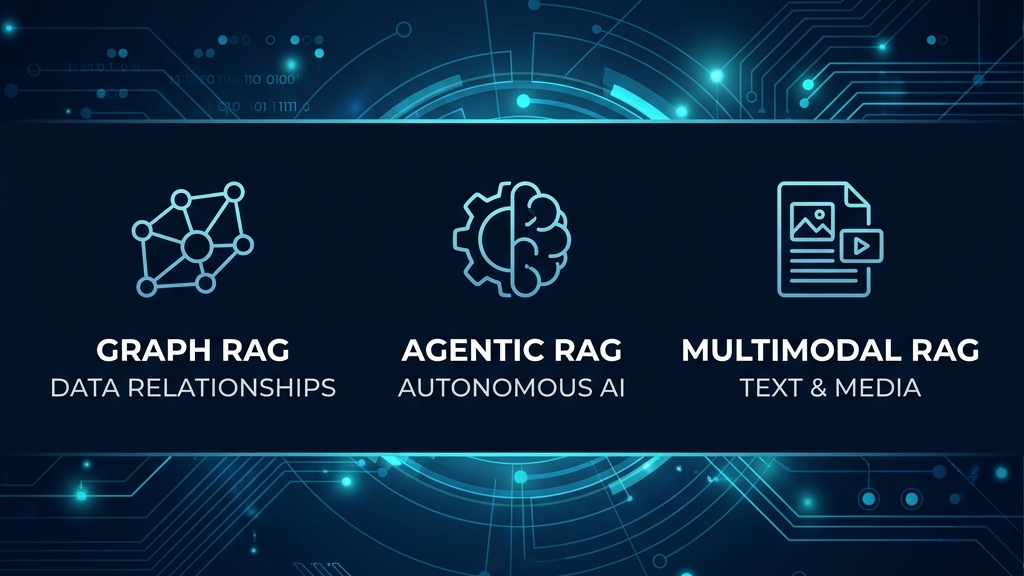
RAGは現在も発展が続いている領域です。GraphRAG、Agentic RAG、マルチモーダルRAGといった考え方が出てきており、企業の情報活用の文脈でも参考になる動向があります。詳細な技術実装には立ち入りませんが、概要として把握しておくと今後の参考になります。
GraphRAG:文書間の関係性を扱うRAG
GraphRAGは、文書や情報の関係性をグラフ構造で扱うRAGの発展形です。単一の文書を検索するだけでなく、複数の情報のつながりを見たい場面で有効とされています。
企業では製品情報と顧客課題、FAQと業務プロセス、採用情報と組織構造といった、情報間の関係を整理して参照したい場面への応用が考えられます。ただし、データ構造を設計・整理する手間は増えます。
Agentic RAG:AIエージェントが検索や判断を組み合わせるRAG
Agentic RAGは、AIエージェントが検索・判断・追加確認を組み合わせて、回答を構築する考え方です。1回の検索で回答を完結させるのではなく、必要に応じて検索を繰り返しながら精度を高めます。
複雑な業務質問や複数の資料をまたぐ判断に向いている考え方です。一方で、権限管理、ログの記録、誤動作への対応体制といった運用設計がより重要になります。
マルチモーダルRAG:画像やPDFなども扱うRAG
マルチモーダルRAGとは、テキストだけでなく、画像・図表・PDFなども参照対象にする考え方です。業務マニュアルの操作画面・研修スライド・製品カタログなど、図解を含む資料との相性が良いのが特徴です。
CSでは操作手順の説明に、L&D領域では研修資料の活用に広がる可能性があります。ただし、画像内テキストの読み取り精度や、資料フォーマットの管理方法には注意が必要です。
RAGを導入する前に情報資産を見直すことが重要
RAGは、社内データや外部データを生成AIで活用する上で有効な仕組みです。しかし、その精度はAIモデルよりも参照するデータの品質に左右されます。社内FAQ、業務マニュアル、研修資料、ヘルプ記事、問い合わせログなどを棚卸しすることが、導入前の重要なステップです。
情報の粒度、更新日、所有者、権限、参照可否を整理しておかないと、RAGは期待通りには機能しません。「まず導入してから整える」よりも、「整えてから導入する」方が立ち上がりの精度が高くなります。
RAG導入を検討している場合は、情報資産の現状を整理するところから始めることをおすすめします。何をどこに持っているか、誰が更新するのか、どこまで参照させてよいかを確認することが、RAG活用の土台になります。
情報資産の整備を進める際には、「RAG導入前の情報整備テンプレート」も参考にしてみてください。社内FAQ、マニュアル、ヘルプ記事などの棚卸しと整理の進め方をまとめています。
RAGに関してよくある質問(FAQ)
Q1. RAGとは何の略ですか?
A.RAGは「Retrieval-Augmented Generation」の略です。日本語では「検索拡張生成」と訳されます。検索で取得した情報を使って、生成AIの回答を拡張する仕組みを指します。
Q2. RAGの読み方は何ですか?
A.一般的には「ラグ」と読みます。文脈によって「アール・エー・ジー」と読むこともありますが、会話の中では「ラグ」が使われることが多いです。
Q3. RAGとChatGPTは何が違いますか?
A.ChatGPTは生成AIのサービスで、RAGは生成AIが外部データを参照するための仕組みです。ChatGPTのような生成AIにRAGの考え方を組み合わせることで、社内情報を参照した回答に近づけられます。どちらかが上位の概念というわけではなく、それぞれ異なる役割を持っています。
Q4. RAGを使えばハルシネーションはなくなりますか?
A.完全になくなるわけではありません。参照情報が正しく整理されており、検索精度が高ければリスクを下げやすくなります。
ただし、参照元が古い、検索結果が不適切、回答ルールが曖昧といった状態では、誤回答は起こり得ます。業務利用では、参照元の確認とレビュー体制を設けることが重要です。
Q5. RAGとファインチューニングはどちらを使うべきですか?
A.社内FAQや最新情報を参照させたいならRAGが向いています。回答の形式や振る舞いを調整したいならファインチューニングも選択肢になります。
どちらが優れているということではなく、目的によって使い分けるものです。企業の社内データ活用では、まずRAGを検討しやすいといえます。
Q6. RAG導入前に何を準備すべきですか?
A.参照させる情報資産の棚卸しが必要です。古い情報・重複情報・権限が曖昧な情報を整理しましょう。その上で、文書の見出し・粒度・更新責任・所有者などを確認します。導入前の情報整備が、RAGの回答精度を大きく左右します。
RAGは社内データを生成AIで活用するための設計が重要
RAGは、生成AIが外部データを検索し、参照して回答する仕組みです。社内FAQ、業務マニュアル、研修資料、ヘルプ記事などの活用に役立ちます。
ただし、RAGの成果はAIモデルだけでは決まりません。参照データの品質、更新責任の明確化、権限設計、運用の継続的な改善が重要です。RAG導入を検討するなら、まず社内情報資産を整理することが出発点になります。







